Trí tuệ nhân tạo đã chuyển đổi từ một thứ xa xỉ thành một thứ cần thiết trong bối cảnh cạnh tranh ngày nay. Sự hiểu biết sâu sắc về nền tảng công nghệ AI là có lợi và quan trọng để tạo ra các sản phẩm tiên tiến có khả năng cách mạng hóa hoạt động kinh doanh. Hãy cùng khám phá chuyên sâu để hiểu mọi thứ về kho công nghệ AI.
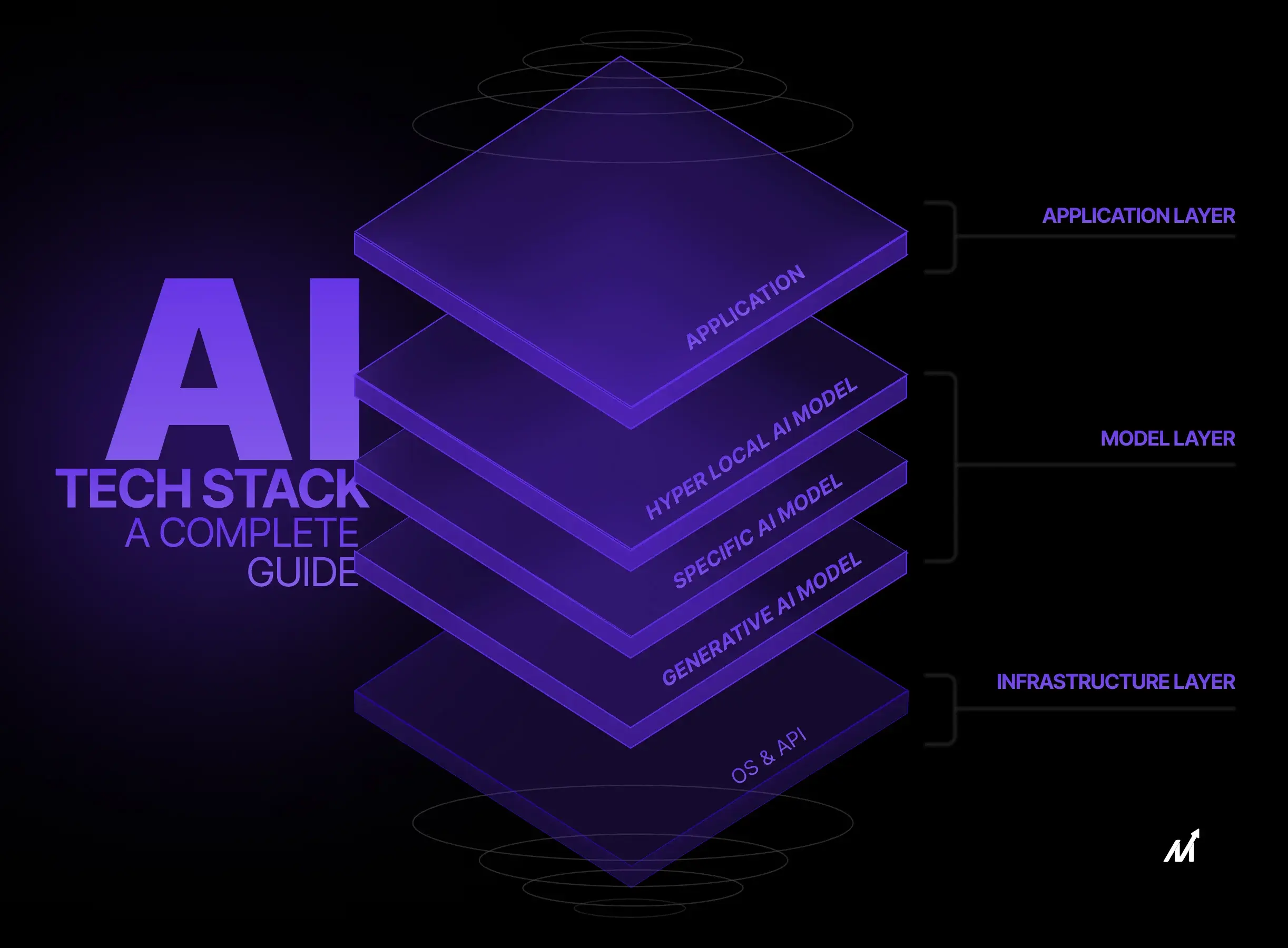
Lớp ngăn xếp công nghệ AI
Ngăn xếp AI là một Framework cấu trúc bao gồm các lớp phụ thuộc lẫn nhau, mỗi lớp phục vụ một chức năng quan trọng để đảm bảo hiệu suất và hiệu suất của hệ thống. Không giống như kiến trúc nguyên khối, trong đó mỗi thành phần được liên kết chặt chẽ và vướng víu, cách tiếp cận theo lớp của ngăn xếp AI cho phép mô-đun hóa, khả năng mở rộng và khắc phục sự cố dễ dàng. Kiến trúc này bao gồm các thành phần quan trọng như nhập dữ liệu, lưu trữ dữ liệu, xử lý dữ liệu, thuật toán Machine Learning , API và giao diện người dùng. Các lớp này đóng vai trò là trụ cột nền tảng hỗ trợ mạng lưới thuật toán, đường dẫn dữ liệu và giao diện ứng dụng phức tạp trong một hệ thống AI điển hình. Chúng ta hãy hiểu sâu hơn về các lớp này.
1. Lớp ứng dụng
Lớp ứng dụng là sự thể hiện trải nghiệm người dùng, đóng gói các thành phần từ ứng dụng web đến API REST quản lý luồng dữ liệu giữa môi trường phía máy khách và phía máy chủ. Lớp này xử lý các hoạt động thiết yếu như thu thập dữ liệu đầu vào thông qua GUI, hiển thị trực quan hóa trên trang tổng quan và cung cấp thông tin chi tiết dựa trên dữ liệu thông qua các điểm cuối API. Các công nghệ như React cho giao diện người dùng và Django cho phụ trợ thường được sử dụng, mỗi công nghệ được chọn vì những ưu điểm cụ thể trong các nhiệm vụ như xác thực dữ liệu, xác thực người dùng và định tuyến yêu cầu API. Lớp ứng dụng đóng vai trò như một cổng định tuyến các yêu cầu của người dùng đến các Mô Hình Machine Learning cơ bản, đồng thời duy trì các giao thức bảo mật nghiêm ngặt để bảo vệ tính toàn vẹn của dữ liệu.
Bài Liên quan




2. Lớp Mô Hình
Chuyển sang Lớp Mô Hình , đây là nơi đưa ra quyết định và xử lý dữ liệu. Các thư viện chuyên biệt như TensorFlow hoặc PyTorch đảm nhận vai trò lãnh đạo ở đây, cung cấp bộ công cụ linh hoạt cho nhiều hoạt động Machine Learning bao gồm nhưng không giới hạn ở khả năng hiểu ngôn ngữ tự nhiên, thị giác máy tính và phân tích dự đoán. Kỹ thuật tính năng, đào tạo Mô Hình và điều chỉnh siêu tham số diễn ra trong miền này. Các thuật toán Machine Learning khác nhau—từ Mô Hình hồi quy đến mạng thần kinh phức tạp—được xem xét kỹ lưỡng về các số liệu hiệu suất như độ chính xác, khả năng thu hồi và điểm F1. Lớp này hoạt động như một trung gian, lấy dữ liệu từ Lớp ứng dụng, thực hiện các tác vụ điện toán chuyên sâu và sau đó đẩy thông tin chi tiết trở lại để hiển thị hoặc xử lý.
3. Lớp cơ sở hạ tầng
Lớp cơ sở hạ tầng là nền tảng cho cả đào tạo Mô Hình và suy luận. Lớp này là nơi các tài nguyên điện toán như CPU, GPU và TPU được phân bổ và quản lý. Khả năng mở rộng, độ trễ và khả năng chịu lỗi được thiết kế ở cấp độ này bằng cách sử dụng các công cụ điều phối như Kubernetes để quản lý vùng chứa.
Về phía đám mây, các dịch vụ như phiên bản EC2 của AWS hoặc bộ tăng tốc dành riêng cho AI của Azure có thể được kết hợp để nâng cao hiệu quả điện toán . Cơ sở hạ tầng này không chỉ đơn thuần là nơi nhận yêu cầu thụ động mà còn là một thực thể năng động được lập trình để phân bổ nguồn lực một cách thận trọng. Cân bằng tải, giải pháp lưu trữ dữ liệu và độ trễ mạng đều được thiết kế để đáp ứng nhu cầu cụ thể của các lớp trên, đảm bảo rằng các tắc nghẽn về sức mạnh điện toán không trở thành trở ngại cho hiệu suất của ứng dụng.
Nhóm công nghệ AI: Các thành phần và mức độ liên quan của chúng
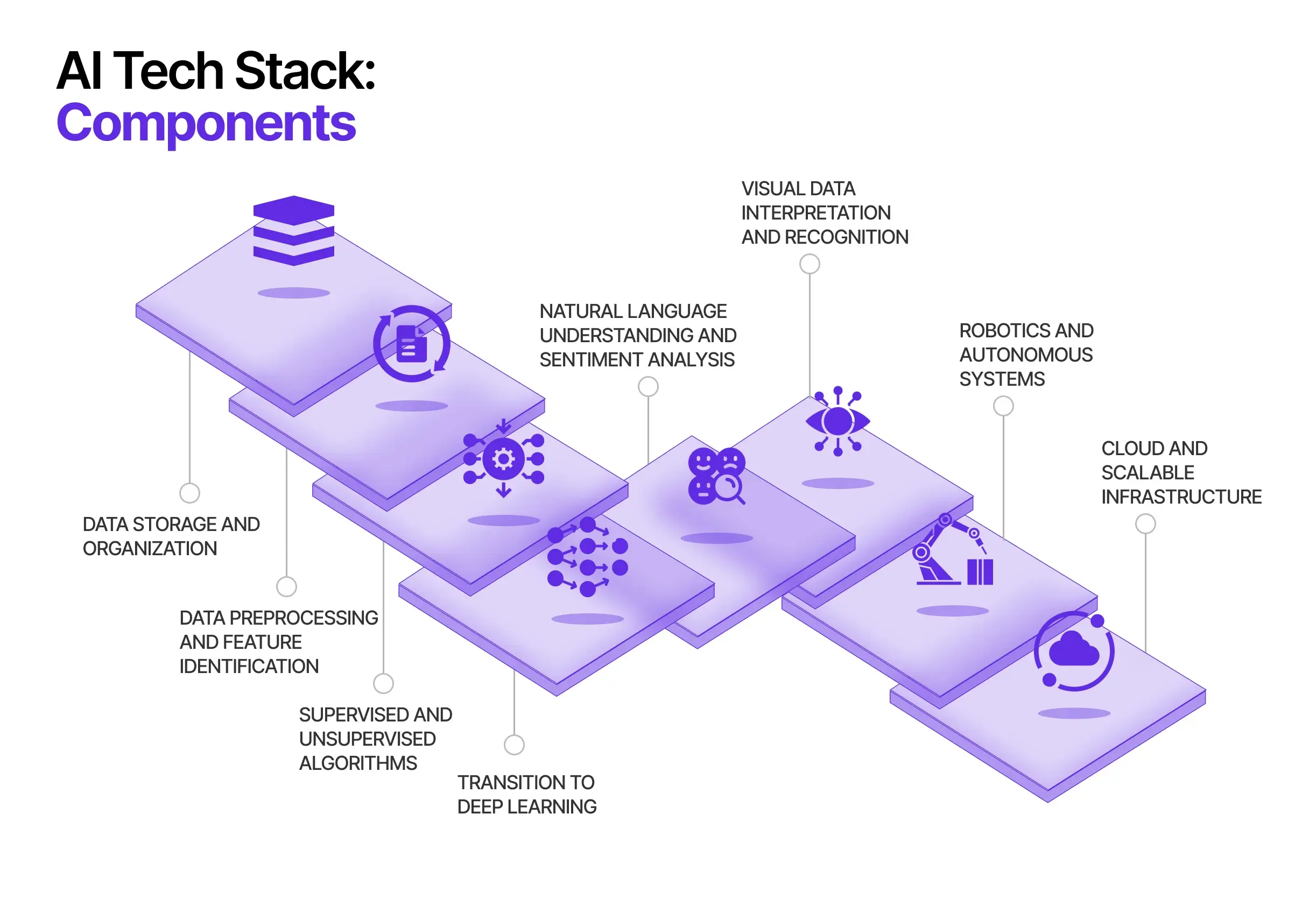
Kiến trúc bao gồm các giải pháp trí tuệ nhân tạo (AI) bao gồm các mô-đun nhiều mặt, mỗi mô-đun chuyên thực hiện các nhiệm vụ riêng biệt nhưng được tích hợp chặt chẽ để có chức năng toàn diện. Sự tinh vi của nhóm công nghệ này là công cụ thúc đẩy các khả năng của AI từ việc nhập dữ liệu đến ứng dụng cuối cùng. Dưới đây là các thành phần khác nhau tạo nên nhóm công nghệ AI:
1. Lưu trữ và tổ chức dữ liệu
Trước khi thực hiện bất kỳ quá trình xử lý AI nào, bước cơ bản là lưu trữ dữ liệu an toàn và hiệu quả. Các giải pháp lưu trữ như cơ sở dữ liệu SQL cho dữ liệu có cấu trúc và cơ sở dữ liệu NoSQL cho dữ liệu phi cấu trúc là rất cần thiết. Đối với dữ liệu quy mô lớn, các giải pháp Dữ liệu lớn như HDFS của Hadoop và xử lý trong bộ nhớ của Spark trở nên cần thiết. Loại lưu trữ được chọn sẽ ảnh hưởng trực tiếp đến tốc độ truy xuất dữ liệu, điều này rất quan trọng đối với quy trình phân tích thời gian thực và máy học.
2. Tiền xử lý dữ liệu và nhận dạng tính năng: Cầu nối cho Machine Learning
Việc lưu trữ sau đây là nhiệm vụ tỉ mỉ của việc tiền xử lý dữ liệu và nhận dạng tính năng. Quá trình tiền xử lý bao gồm việc chuẩn hóa, xử lý các giá trị bị thiếu và phát hiện ngoại lệ—các bước này được thực hiện bằng các thư viện như Scikit-learn và Pandas trong Python.
Nhận dạng tính năng là mấu chốt để giảm kích thước và được thực hiện bằng cách sử dụng các kỹ thuật như Phân tích thành phần chính (PCA) hoặc Xếp hạng tầm quan trọng của tính năng. Các tính năng được làm sạch và tinh gọn này trở thành đầu vào cho các thuật toán Machine Learning , đảm bảo độ chính xác và hiệu quả cao hơn.
3. Thuật toán được giám sát và không được giám sát: Cốt lõi của Mô Hình hóa dữ liệu
Sau khi có sẵn dữ liệu được xử lý trước, các thuật toán Machine Learning sẽ được sử dụng. Các thuật toán như Máy vectơ hỗ trợ (SVM) để phân loại, Random Forest để học tổng hợp và phương tiện k để phân cụm phục vụ các vai trò cụ thể trong Mô Hình hóa dữ liệu. Việc lựa chọn thuật toán ảnh hưởng trực tiếp đến hiệu quả điện toán và độ chính xác dự đoán, do đó phải phù hợp với yêu cầu của bài toán.
4. Học sâu – Deep Learning : Mô Hình điện toán nâng cao
Khi các vấn đề điện toán ngày càng phức tạp, các thuật toán Machine Learning truyền thống có thể bị thiếu hụt. Điều này đòi hỏi phải sử dụng các framework deep learning như TensorFlow, PyTorch hoặc Keras. Các Framework này hỗ trợ xây dựng và đào tạo các kiến trúc mạng thần kinh phức tạp như Mạng thần kinh chuyển đổi (CNN) để nhận dạng hình ảnh hoặc Mạng thần kinh tái phát (RNN) để phân tích dữ liệu tuần tự.
5. Hiểu ngôn ngữ tự nhiên và phân tích cảm xúc: Giải mã bối cảnh con người
Khi nói đến việc diễn giải ngôn ngữ của con người, các thư viện Xử lý ngôn ngữ tự nhiên (NLP) như NLTK và spaCy đóng vai trò là lớp nền tảng. Đối với các ứng dụng nâng cao hơn như phân tích cảm xúc, các Mô Hình dựa trên máy biến áp như GPT-4 hoặc BERT mang lại mức độ hiểu biết và nhận dạng ngữ cảnh cao hơn. Các công cụ và Mô Hình NLP này thường được tích hợp vào nhóm AI theo các thành phần học sâu dành cho các ứng dụng yêu cầu tương tác ngôn ngữ tự nhiên.
6. Giải thích và nhận dạng dữ liệu trực quan: Tạo cảm giác về thế giới
Trong lĩnh vực dữ liệu trực quan, các công nghệ thị giác máy tính như OpenCV là không thể thiếu. Các ứng dụng nâng cao có thể tận dụng CNN để nhận dạng khuôn mặt, phát hiện đối tượng, v.v. Các thành phần thị giác máy tính này thường hoạt động song song với các thuật toán Machine Learning để cho phép diễn giải dữ liệu đa phương thức.
7. Robot và hệ thống tự động: Ứng dụng trong thế giới thực
Đối với các ứng dụng vật lý như robot và hệ thống tự động, kỹ thuật tổng hợp cảm biến được tích hợp vào ngăn xếp. Các thuật toán Bản đồ hóa và Bản đồ hóa Đồng thời (SLAM) và các thuật toán ra quyết định như Tìm kiếm cây Monte Carlo (MCTS) được triển khai. Các yếu tố này hoạt động cùng với các thành phần máy học và thị giác máy tính, thúc đẩy khả năng tương tác của AI với môi trường của nó.
8. Cơ sở hạ tầng đám mây và có thể mở rộng: Nền tảng của hệ thống AI
Toàn bộ nhóm công nghệ AI thường hoạt động trong cơ sở hạ tầng dựa trên đám mây như AWS, Google Cloud hoặc Azure. Các nền tảng này cung cấp các tài nguyên điện toán theo yêu cầu, có thể mở rộng, rất quan trọng cho việc lưu trữ dữ liệu, tốc độ xử lý và thực thi thuật toán. Cơ sở hạ tầng đám mây đóng vai trò là lớp hỗ trợ cho phép tất cả các thành phần trên hoạt động liền mạch và tích hợp.
Nền tảng hệ sinh thái AI: Kế hoạch chi tiết để phát triển ứng dụng thông minh
Về cơ bản, một kho công nghệ AI có kiến trúc tốt bao gồm các Framework ứng dụng nhiều mặt cung cấp Mô Hình lập trình được tối ưu hóa, dễ dàng thích ứng với những phát triển công nghệ mới nổi. Các Framework như vậy, bao gồm LangChain, Fixie, Semantic Kernel của Microsoft và Vertex AI của Google Cloud, trang bị cho các kỹ sư xây dựng các ứng dụng được trang bị để tạo nội dung tự động, hiểu ngữ nghĩa cho các truy vấn tìm kiếm ngôn ngữ tự nhiên và thực hiện nhiệm vụ thông qua các tác nhân thông minh.
1. Mô-đun trí tuệ điện toán : Lớp nhận thức
Nằm ở trung tâm của nhóm công nghệ AI là Mô Hình nền tảng (FM), về cơ bản đóng vai trò là lớp nhận thức cho phép đưa ra quyết định phức tạp và suy luận logic. Cho dù đó là những sáng tạo nội bộ của các doanh nghiệp như Open AI, Anthropic hay Cohere hay các lựa chọn thay thế nguồn mở, những Mô Hình này đều cung cấp nhiều khả năng. Các kỹ sư có thể tận dụng nhiều FM để nâng cao hiệu suất ứng dụng. Các tùy chọn triển khai bao gồm cả kiến trúc máy chủ tập trung và điện toán biên, mang lại các lợi ích như giảm độ trễ và cải thiện tính bảo mật.
2. Vận hành dữ liệu: Thúc đẩy động cơ nhận thức
Mô Hình học ngôn ngữ (LLM) có khả năng đưa ra suy luận dựa trên dữ liệu đào tạo của họ. Để tối đa hóa hiệu quả và độ chính xác, các kỹ sư phải thiết lập các giao thức vận hành dữ liệu mạnh mẽ. Trình tải dữ liệu, cơ sở dữ liệu vectơ và các công cụ tương tự trở thành công cụ để tiếp thu cả tập dữ liệu có cấu trúc và không cấu trúc, tạo điều kiện thuận lợi cho việc thực hiện truy vấn và lưu trữ hiệu quả. Hơn nữa, các công nghệ như thế hệ tăng cường truy xuất sẽ thêm một lớp tùy chỉnh khác vào đầu ra của Mô Hình .
2. Cơ chế đánh giá hiệu suất: Các thước đo định lượng và định tính
Việc điều hướng sự cân bằng giữa hiệu quả của Mô Hình , chi tiêu tài chính và độ trễ phản hồi là một trở ngại đáng kể trong lĩnh vực AI tạo ra. Các kỹ sư sử dụng một loạt tiện ích chẩn đoán để tinh chỉnh sự cân bằng này, bao gồm tối ưu hóa nhanh chóng, phân tích hiệu suất theo thời gian thực và theo dõi thử nghiệm. Vì những mục đích này, vô số công cụ Không mã/Mã thấp, tiện ích theo dõi và nền tảng chuyên biệt như LangKit của WhyLabs đều được các nhà phát triển tùy ý sử dụng.
3. Chuyển sang vận hành : Giai đoạn triển khai cuối cùng
Mục tiêu cuối cùng trong quy trình phát triển là chuyển các ứng dụng từ giai đoạn thử nghiệm sang môi trường sản xuất trực tiếp. Các kỹ sư có thể linh hoạt lựa chọn tự lưu trữ hoặc có thể tranh thủ các dịch vụ triển khai của bên thứ ba. Nhiều người hỗ trợ khác nhau như Fixie hợp lý hóa các giai đoạn xây dựng, phổ biến và triển khai trong quá trình triển khai ứng dụng AI.
Tóm lại, nhóm công nghệ AI là một cơ sở hạ tầng toàn diện, hỗ trợ vòng đời tạo ứng dụng thông minh từ khâu lên ý tưởng đến sản xuất trực tiếp. Hệ thống phức tạp này cung cấp nền tảng kỹ thuật cách mạng hóa cách xây dựng ứng dụng, cách tổng hợp thông tin diễn ra và cách thực hiện nhiệm vụ. Nó thể hiện một phương pháp biến đổi nhằm xác định lại cả bối cảnh công nghệ và phương thức hoạt động của môi trường làm việc hiện đại.
AI Tech Stack – Sự cần thiết để thành công trong AI
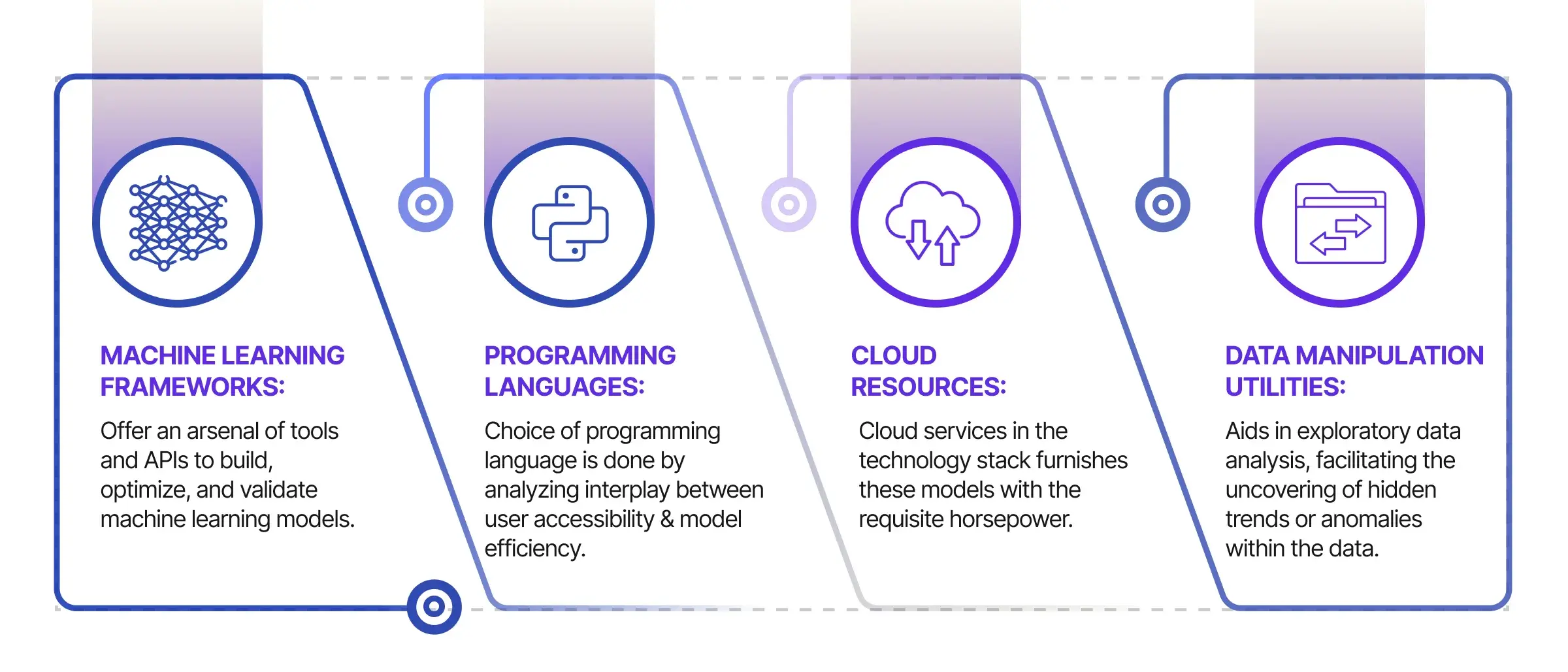
Không thể phóng đại sự cần thiết của một hệ thống công nghệ được quản lý tỉ mỉ trong việc xây dựng các hệ thống AI mạnh mẽ. Từ Framework Machine Learning đến ngôn ngữ lập trình, dịch vụ đám mây và tiện ích thao tác dữ liệu, mỗi thành phần đều đóng một vai trò then chốt. Dưới đây là bảng phân tích kỹ thuật của các thành phần quan trọng này.
1. Framework Machine Learning
Kiến trúc của các Mô Hình AI đòi hỏi phải có các Framework Machine Learning tiên tiến để đào tạo và suy luận. TensorFlow, PyTorch và Keras không chỉ là những thư viện; chúng là các hệ sinh thái cung cấp kho công cụ và Giao diện lập trình ứng dụng (API) để xây dựng, tối ưu hóa và xác thực các Mô Hình Machine Learning . Họ cũng lưu trữ một loạt các Mô Hình được cấu hình sẵn cho các tác vụ từ xử lý ngôn ngữ tự nhiên đến thị giác máy tính. Các khuôn khổ như vậy phải tạo thành nền tảng của nhóm công nghệ, cung cấp các phương pháp điều chỉnh Mô Hình cho các số liệu cụ thể như độ chính xác, khả năng thu hồi hoặc điểm F1.
2. Ngôn ngữ lập trình
Việc lựa chọn ngôn ngữ lập trình là kết quả của sự tương tác hài hòa giữa khả năng tiếp cận của người dùng và hiệu quả của Mô Hình . Python được coi là ngôn ngữ chung của máy học nhờ tính dễ đọc và kho lưu trữ gói đầy đủ. Trong khi Python chiếm ưu thế, các ngôn ngữ như R và Julia cũng tìm thấy các ứng dụng, đặc biệt là cho các nhiệm vụ phân tích thống kê và điện toán hiệu năng cao.
3. Tài nguyên đám mây
Nhu cầu điện toán và lưu trữ của các Mô Hình AI tổng quát là không hề nhỏ. Việc tích hợp các dịch vụ đám mây trong kho công nghệ mang lại cho các Mô Hình này sức mạnh cần thiết. Các dịch vụ như Amazon Web Services (AWS), Google Cloud Platform (GCP) và Microsoft Azure hiển thị các tài nguyên có thể định cấu hình như máy ảo, cùng với các nền tảng máy học chuyên dụng. Khả năng mở rộng vốn có của cơ sở hạ tầng đám mây đảm bảo rằng hệ thống AI có thể thích ứng với các khối lượng công việc khác nhau mà không làm giảm hiệu suất hoặc phát sinh thời gian ngừng hoạt động.
4. Tiện ích thao tác dữ liệu
Dữ liệu thô hiếm khi sẵn sàng cho việc đào tạo Mô Hình ngay lập tức; các bước tiền xử lý như chuẩn hóa, mã hóa và quy định thường là bắt buộc. Các tiện ích như Apache Spark và Apache Hadoop cung cấp khả năng xử lý dữ liệu có thể quản lý hiệu quả các tập dữ liệu khổng lồ. Chức năng bổ sung của họ để hỗ trợ trực quan hóa dữ liệu trong việc phân tích dữ liệu khám phá, tạo điều kiện phát hiện các xu hướng hoặc điểm bất thường ẩn trong dữ liệu.
Bằng cách lựa chọn và tích hợp các thành phần này một cách có phương pháp vào một khối công nghệ gắn kết, người ta không chỉ đạt được một hệ thống AI chức năng mà còn đạt được một hệ thống được tối ưu hóa. Do đó, hệ thống được lắp ráp sẽ thể hiện độ chính xác được nâng cao, khả năng mở rộng và độ tin cậy cao hơn, những điều không thể thiếu cho sự phát triển và triển khai nhanh chóng các ứng dụng AI. Chính sự kết hợp của các tài nguyên được lựa chọn kỹ lưỡng này đã tạo nên một kho công nghệ không chỉ toàn diện mà còn là công cụ giúp đạt được hiệu suất cao nhất trong các hệ thống AI.
Các giai đoạn của nhóm công nghệ AI hiện đại
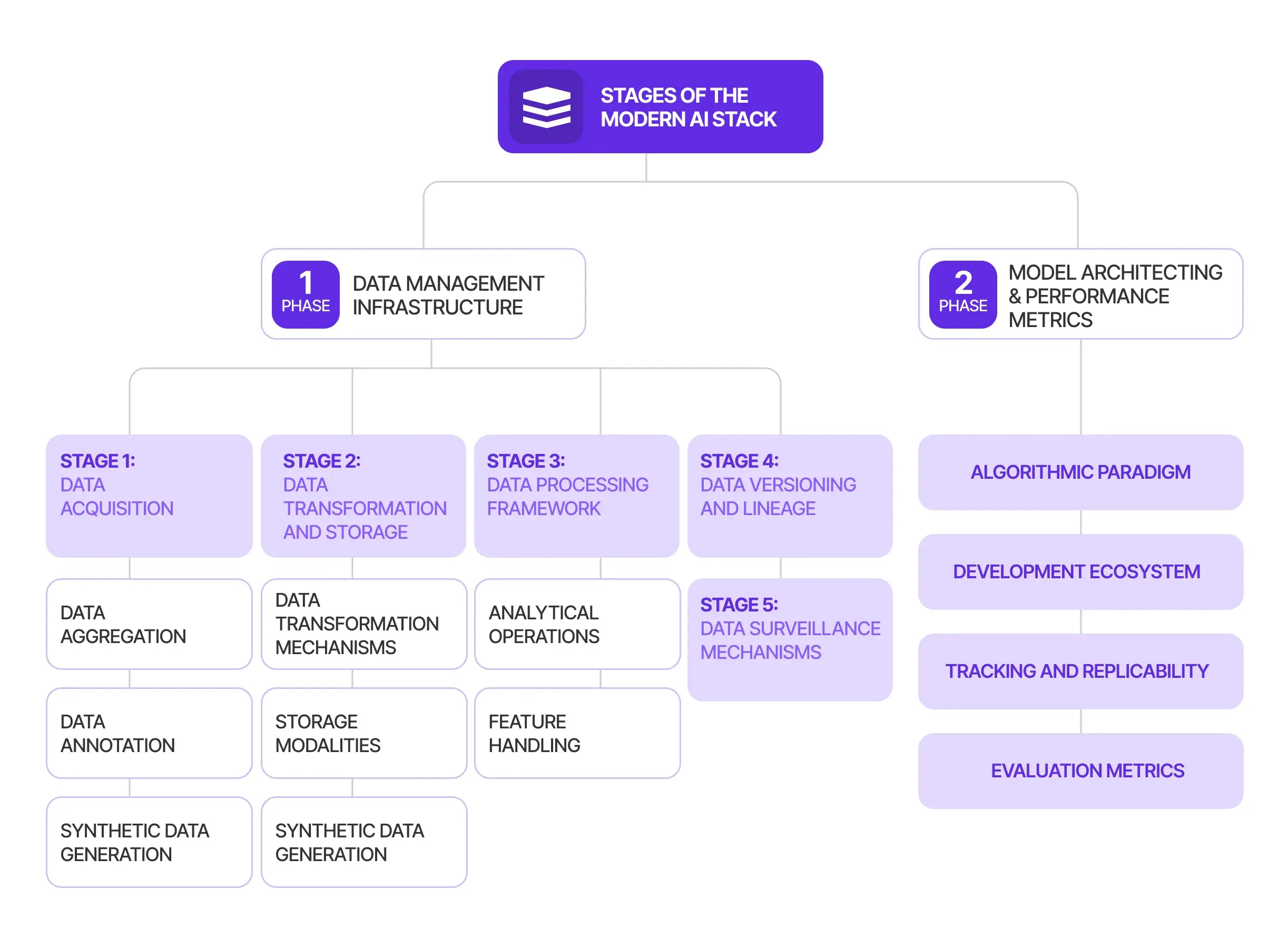
Để xây dựng, triển khai và mở rộng quy mô các giải pháp AI một cách hiệu quả, không thể thiếu một khuôn khổ mang tính hệ thống. Cấu trúc phức tạp này đóng vai trò là xương sống cho các ứng dụng AI, cung cấp cách tiếp cận theo từng lớp để giải quyết các thách thức nhiều mặt do quá trình phát triển AI đặt ra. Framework này thường được chia thành các giai đoạn riêng biệt, mỗi giai đoạn chịu trách nhiệm về một khía cạnh cụ thể của vòng đời AI, chẳng hạn như quản lý dữ liệu, chuyển đổi dữ liệu và Machine Learning , cùng những khía cạnh khác. Hãy hiểu từng giai đoạn này để hiểu tầm quan trọng, công cụ và phương pháp của từng lớp.
Giai đoạn một: Cơ sở hạ tầng quản lý dữ liệu
Dữ liệu là huyết mạch thúc đẩy các thuật toán Machine Learning , phân tích và cuối cùng là đưa ra quyết định. Do đó, giai đoạn đầu tiên trong cuộc thảo luận về Ngăn xếp AI của chúng tôi xoay quanh Cơ sở hạ tầng quản lý dữ liệu, một phân khúc quan trọng để thu thập, tinh chỉnh và biến dữ liệu thành hành động. Giai đoạn này có thể được chia thành nhiều giai đoạn, mỗi giai đoạn tập trung vào một khía cạnh cụ thể của việc xử lý dữ liệu, bao gồm Thu thập dữ liệu, Chuyển đổi và lưu trữ dữ liệu cũng như Framework xử lý dữ liệu. Dưới đây, chúng tôi mổ xẻ từng giai đoạn để cung cấp sự hiểu biết toàn diện về cơ chế, công cụ và tầm quan trọng của nó.
Giai đoạn 1. Thu thập dữ liệu
1.1 Tổng hợp dữ liệu
Cơ chế thu thập dữ liệu là một sự tương tác phức tạp liên quan đến sự hợp nhất các bộ công cụ bên trong và các ứng dụng bên ngoài. Các nguồn khác nhau này kết hợp lại để quản lý một tập dữ liệu hữu ích cho các hoạt động tiếp theo.
1.2 Chú thích dữ liệu
Dữ liệu được thu thập phải tuân theo quy trình ghi nhãn, quy trình này rất cần thiết cho quá trình học tập dựa trên máy trong môi trường được giám sát. Tự động hóa đã dần dần đảm nhận nhiệm vụ tốn nhiều công sức này thông qua các giải pháp phần mềm như V7 Labs và ImgLab. Tuy nhiên, việc giám sát thủ công vẫn không thể thiếu do những hạn chế về mặt thuật toán trong việc xác định các trường hợp ngoại lệ.
1.3 Tạo dữ liệu tổng hợp
Bất chấp khối lượng dữ liệu sẵn có khổng lồ, vẫn tồn tại những khoảng trống, đặc biệt là trong các trường hợp sử dụng thích hợp. Do đó, các công cụ như Tensorflow và OpenCV đã được sử dụng để tạo dữ liệu hình ảnh tổng hợp. Các thư viện như SymPy và Pydbgen được triển khai dưới dạng biểu thức tượng trưng và dữ liệu phân loại. Các tiện ích bổ sung như Hazy và Datomize cung cấp khả năng tích hợp với các nền tảng khác.
Giai đoạn 2. Chuyển đổi và lưu trữ dữ liệu
2.1 Cơ chế chuyển đổi dữ liệu
ETL và ELT đóng vai trò là hai Mô Hình tương phản để chuyển đổi dữ liệu. ETL ưu tiên sàng lọc dữ liệu, tạm thời sắp xếp dữ liệu để xử lý trước khi lưu trữ lần cuối. Ngược lại, ELT tập trung vào tính thực tế, lưu trữ dữ liệu trước tiên và chuyển đổi nó. Reverse ETL đã xuất hiện để đồng bộ hóa các kho lưu trữ dữ liệu với giao diện người dùng cuối như CRM và ERP, dân chủ hóa dữ liệu trên các ứng dụng.
2.2 Phương thức lưu trữ
Có nhiều phương pháp khác nhau để lưu trữ dữ liệu, mỗi phương pháp đáp ứng một nhu cầu cụ thể. Các hồ dữ liệu vượt trội trong việc lưu trữ dữ liệu phi cấu trúc, trong khi kho dữ liệu được thiết kế riêng để lưu trữ dữ liệu có cấu trúc, được xử lý cao. Một loạt giải pháp dựa trên đám mây như Google Cloud Platform và Azure Cloud cung cấp khả năng lưu trữ mạnh mẽ.
Giai đoạn 3. Framework xử lý dữ liệu
3.1 Hoạt động phân tích
Dữ liệu sau khi thu thập phải được xử lý thành dạng dễ tiêu hóa. Các thư viện như NumPy và pandas được sử dụng rộng rãi cho giai đoạn phân tích dữ liệu này. Để xử lý dữ liệu tốc độ cao, Apache Spark đóng vai trò là một công cụ mạnh mẽ.
3.2 Xử lý tính năng
Các cửa hàng tính năng như Iguazio, Tecton và Feast là nền tảng của việc quản lý tính năng hiệu quả, nâng cao đáng kể độ tin cậy của các quy trình tính năng trên các ứng dụng Machine Learning .
Giai đoạn 4. Phiên bản dữ liệu và dòng dõi
Lập phiên bản vẫn là nền tảng trong quản lý dữ liệu, tạo điều kiện cho khả năng tái tạo trong môi trường dữ liệu luôn thay đổi. Các công cụ như DVC không phụ thuộc vào công nghệ, tích hợp hoàn hảo với nhiều phương tiện lưu trữ khác nhau. Về mặt dòng dữ liệu, các nền tảng như Pachyderm cung cấp phiên bản dữ liệu và cung cấp bản đồ phức tạp về dòng dữ liệu, trình bày một bản tường thuật dữ liệu mạch lạc.
Giai đoạn 5. Cơ chế giám sát dữ liệu
Các giải pháp giám sát tự động như Điều tra dân số là công cụ giúp duy trì chất lượng dữ liệu, xác định những khác biệt như thiếu giá trị, xung đột loại hoặc biến thể thống kê. Các công cụ giám sát bổ sung như Fiddler và Grafana phục vụ các mục đích tương tự nhưng thêm một lớp Độ phức tạp bằng cách theo dõi lưu lượng truy cập dữ liệu.
Giai đoạn 2: Kiến trúc Mô Hình và đo lường hiệu suất
Lập Mô Hình trong bối cảnh trí tuệ nhân tạo và Machine Learning không phải là một quá trình tuyến tính mà là một quá trình mang tính chu kỳ bao gồm các tiến bộ và đánh giá lặp đi lặp lại. Nó bắt đầu sau khi dữ liệu được tích lũy, lưu trữ, xem xét kỹ lưỡng và chuyển thành các thuộc tính chức năng. Việc phát triển Mô Hình không chỉ là lựa chọn thuật toán mà còn là lăng kính của các ràng buộc điện toán , điều kiện hoạt động và quản trị bảo mật dữ liệu.
2.1 Mô Hình thuật toán
Machine Learning đi kèm với các thư viện mở rộng như TensorFlow, PyTorch, scikit-learn và MXNET, mỗi thư viện đều cung cấp các ưu điểm độc đáo—tốc độ điện toán , tính linh hoạt, đường cong dễ học hoặc sự hỗ trợ mạnh mẽ của cộng đồng. Sau khi thư viện phù hợp với yêu cầu của dự án, người ta có thể bắt đầu các quy trình thông thường về lựa chọn Mô Hình , điều chỉnh tham số và thử nghiệm lặp lại.
2.2 Hệ sinh thái phát triển
Môi trường phát triển tích hợp (IDE) hỗ trợ phát triển AI và phần mềm . Nó tích hợp các thành phần thiết yếu—trình soạn thảo mã, cơ chế biên dịch, công cụ gỡ lỗi, v.v.—hợp lý hóa quy trình phát triển. PyCharm nổi bật nhờ tính dễ dàng trong việc quản lý phụ thuộc và liên kết mã, đảm bảo dự án vẫn ổn định, ngay cả khi chuyển đổi giữa các nhà phát triển hoặc nhóm khác nhau.
Visual Studio Code (VS Code) nổi lên như một IDE đáng tin cậy khác, có tính linh hoạt cao trên các hệ điều hành và cung cấp khả năng tích hợp với các tiện ích bên ngoài như PyLint và Node.js. Các IDE khác như Jupyter và Spyder chủ yếu được sử dụng trong giai đoạn tạo mẫu. Vốn là một phần mềm được yêu thích trong học thuật, MATLAB đang dần dần có chỗ đứng trong các ứng dụng thương mại để hỗ trợ mã đầu cuối.
2.3 Theo dõi và khả năng nhân rộng
Ngăn xếp công nghệ Machine Learning vốn mang tính thử nghiệm, đòi hỏi nhiều thử nghiệm trên các tập hợp con dữ liệu, kỹ thuật tính năng và phân bổ tài nguyên để tinh chỉnh Mô Hình tối ưu. Khả năng tái tạo các thí nghiệm là rất quan trọng để tìm lại quỹ đạo phát triển và triển khai sản xuất.
Các công cụ như MLFlow, Neptune và Weights & Biases tạo điều kiện thuận lợi cho việc theo dõi thử nghiệm nghiêm ngặt. Đồng thời, Layer cung cấp nền tảng tổng thể để quản lý tất cả siêu dữ liệu của dự án. Điều này đảm bảo một hệ sinh thái hợp tác có thể thích ứng linh hoạt theo quy mô, một trọng tâm quan trọng đối với các công ty hướng tới các dự án Machine Learning hợp tác, mạnh mẽ.
2.4 Các thước đo đánh giá
Đánh giá hiệu suất trong Machine Learning bao gồm các so sánh phức tạp giữa nhiều kết quả thử nghiệm và phân chia dữ liệu. Các công cụ tự động như Comet, Evidently AI và Censius đóng một vai trò quan trọng ở đây. Các tiện ích này tự động hóa việc giám sát, cho phép các nhà khoa học dữ liệu tập trung vào các mục tiêu cốt lõi thay vì theo dõi hiệu suất thủ công.
Các nền tảng này cung cấp các đánh giá số liệu tiêu chuẩn và có thể tùy chỉnh, phù hợp với các trường hợp sử dụng chung và nhiều sắc thái. Việc nêu chi tiết các vấn đề về hiệu suất về các thách thức khác, chẳng hạn như suy giảm chất lượng dữ liệu hoặc sai lệch Mô Hình , trở nên không thể thiếu trong phân tích nguyên nhân gốc rễ.
Tiêu chí để chọn nhóm công nghệ AI
1. Thông số kỹ thuật và chức năng
Việc xác định các thông số kỹ thuật và chức năng của dự án đóng một vai trò quan trọng trong việc lựa chọn nhóm công nghệ AI. Tầm quan trọng và tham vọng của dự án đòi hỏi mức độ phức tạp tương ứng trong hệ thống — từ ngôn ngữ lập trình đến các Framework được sử dụng. Liên quan đến AI tổng quát, sau đây là các thông số cốt lõi cần đánh giá:
- Phương thức dữ liệu: Liệu hệ thống AI sẽ tạo ra hình ảnh, văn bản hay âm thanh sẽ quyết định cách tiếp cận thuật toán—GAN cho các thành phần hình ảnh và RNN hoặc LSTM cho dữ liệu văn bản hoặc thính giác.
- Độ phức tạp điện toán : Các yếu tố như số lượng đầu vào, lớp thần kinh và khối lượng dữ liệu đòi hỏi phải có kiến trúc phần cứng mạnh mẽ, có khả năng đòi hỏi GPU và framework như TensorFlow hoặc PyTorch.
- Yêu cầu về khả năng mở rộng: Trong những trường hợp đòi hỏi khả năng điện toán linh hoạt cao—chẳng hạn như tạo ra các biến thể dữ liệu hoặc đáp ứng nhiều người dùng—cơ sở hạ tầng dựa trên đám mây như AWS, Google Cloud Platform hoặc Azure trở nên bắt buộc.
- Số liệu chính xác: Đối với các ứng dụng quan trọng như phát triển thuốc hoặc điều hướng tự động, các kỹ thuật tạo sinh có độ chính xác cao như VAE hoặc RNN được ưu tiên.
- Tốc độ thực thi: Đối với các ứng dụng thời gian thực, như truyền phát video hoặc tác nhân đàm thoại, các chiến lược tối ưu hóa để tăng tốc suy luận Mô Hình là rất quan trọng.
2. Năng lực và tài sản
Các kỹ năng và nguồn lực có sẵn cho nhóm phát triển là yếu tố then chốt trong việc lựa chọn nhóm AI. Việc ra quyết định phải mang tính chiến lược, loại bỏ mọi đường cong học tập dốc có thể cản trở sự tiến bộ. Những cân nhắc trong lĩnh vực này bao gồm:
- Chuyên môn của nhóm: Căn chỉnh nhóm phù hợp với trình độ thành thạo của nhóm về các ngôn ngữ hoặc Framework cụ thể để đẩy nhanh tiến độ phát triển.
- Tài nguyên phần cứng: Nếu có thể truy cập GPU hoặc phần cứng chuyên dụng khác, hãy xem xét các Framework điện toán nâng cao hơn.
- Hệ sinh thái hỗ trợ: Đảm bảo rằng nhóm công nghệ đã chọn có tài liệu, hướng dẫn toàn diện và cộng đồng để hỗ trợ khắc phục các tắc nghẽn.
- Ràng buộc tài chính: Những hạn chế về ngân sách có thể đòi hỏi phải có hệ thống công nghệ hiệu quả nhưng hiệu quả về mặt chi phí.
- Độ phức tạp của việc bảo trì: Việc cập nhật và hỗ trợ sau triển khai phải đơn giản và được hỗ trợ bởi cộng đồng hoặc nhà cung cấp đáng tin cậy.
3. Khả năng mở rộng hệ thống
Khả năng mở rộng của hệ thống ảnh hưởng trực tiếp đến tuổi thọ và khả năng thích ứng của nó. Ngăn xếp tối ưu phải tính đến khả năng mở rộng theo chiều dọc—hiệu suất được nâng cao trên nhiều thiết bị—và khả năng mở rộng theo chiều ngang—dễ dàng tăng cường tính năng. Các biến quan trọng cần xem xét bao gồm:
- Khối lượng dữ liệu: Các bộ dữ liệu lớn có thể cần các Framework điện toán phân tán như Apache Spark để thao tác hiệu quả.
- Lưu lượng người dùng: Yêu cầu đồng thời người dùng cao đối với các kiến trúc có thể quản lý lượng yêu cầu đáng kể, có thể yêu cầu thiết kế dịch vụ vi mô hoặc dựa trên đám mây.
- Xử lý thời gian thực: Các yêu cầu xử lý dữ liệu tức thời sẽ hướng dẫn việc lựa chọn các Mô Hình nhẹ hoặc tối ưu hóa hiệu suất.
- Hoạt động hàng loạt: Các hệ thống yêu cầu hoạt động hàng loạt thông lượng cao có thể được hưởng lợi từ các Framework điện toán phân tán để xử lý dữ liệu hiệu quả.
4. Bảo mật và tuân thủ thông tin
Môi trường dữ liệu an toàn là điều tối quan trọng, đặc biệt khi xử lý thông tin tài chính hoặc nhạy cảm. Các tiêu chí bảo mật cần thiết cần xem xét bao gồm:
- Tính toàn vẹn dữ liệu: Chọn các ngăn xếp cung cấp mã hóa mạnh mẽ, quyền truy cập dựa trên vai trò và che giấu dữ liệu để bảo vệ khỏi thao tác dữ liệu trái phép.
- Bảo mật Mô Hình : Các Mô Hình AI tạo thành tài sản trí tuệ có giá trị, yêu cầu các tính năng ngăn chặn truy cập trái phép hoặc giả mạo.
- Bảo vệ cơ sở hạ tầng: Tường lửa, hệ thống phát hiện xâm nhập và các công cụ an ninh mạng khác là cần thiết để củng cố cơ sở hạ tầng hoạt động.
- Tuân thủ quy định: Tùy thuộc vào lĩnh vực—chẳng hạn như chăm sóc sức khỏe hoặc tài chính—ngăn xếp phải tuân thủ các quy định cụ thể của ngành như HIPAA hoặc PCI-DSS.
- Cơ chế xác thực: Các giao thức ủy quyền và xác thực người dùng mạnh mẽ đảm bảo rằng chỉ những nhân viên được ủy quyền mới có thể giao tiếp với hệ thống và dữ liệu của nó.
Nguồn: AI Tech – Markovate





















